
NLP
BERT
- Bidirectional Encoder Representations Form Transformer
- transformer의 encoder만 사용한다.
- Pre-traning과 fine-tuning으로 활용한다.
-
즉, transformer의 encoder을 사전학습(UL) 시킨 언어 모델로, AE처럼 목적에 맞게 활용할 수 있도록 해둔 것이다. 특정 과제의 성능을 더 좋게 할 수 있는 언어 모델이다.
- transformer의 encoder 출력 = BERT의 출력
- transformer의 encoder 부분만 Pre-traning 하여 사용, 실제 사용할 때는 W만 빼내는 fine-tuning 방법으로 응용한다.
BERT등장 이전에는 데이터의 전처리 임베딩을 Word2Vec, GloVe, Fasttext 방식을 많이 사용했지만, 요즘의 고성능을 내는 대부분의 모델에서 BERT를 많이 사용하고 있다고 합니다.
- BERT는 이미 총3.3억 단어(BookCorpus + Wikipedia Data)의 거대한 코퍼스를 정제하고, 임베딩하여 학습시킨 모델이 있다. 따라서 새로운 단어를 추가하거나 기타 등등등의 이유로 필요할 때 BERT 기법을 적용하기 위해 작동 원리를 배운다.
-
AR(Autoregressive) : 과거 데이터로부터 현재 데이터를 추정할 수 있다.
참고: 기존의 ELMO나 GPT는 left to right or right to left Language Model을 사용하여 pre-training을 하지만, BERT는 이와 다르게 2가지의 새로운 unsupervised prediction task로 pre-training을 수행합니다.
알고리즘 원리
Input 단계
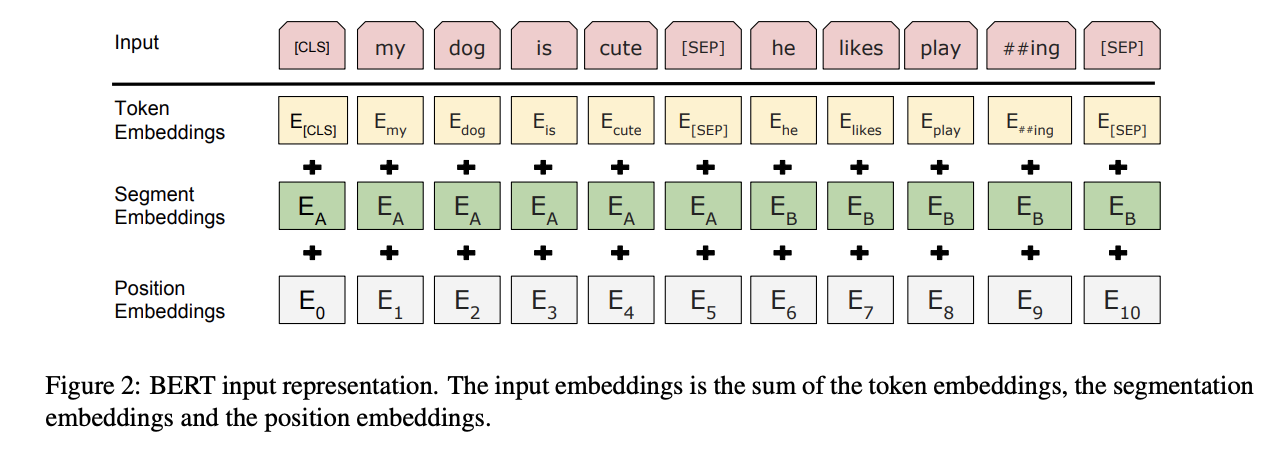
BERT는 아래 세가지 임베딩을 합치고, Layer에 정규화와 Dropout을 적용하여 입력값으로 사용한다. 출처: ebb and flow
-
Token Embedding>"[
Word Piece]. 임베딩 방식 사용한다. 즉, 각 Char(문자) 단위로 임베딩한다."- SubWord
Step 1. 자주 등장하면서 가장 긴 길이로 단어를 분리한다.
Step 2. 자주 등장하지 않았던 단어도 분리한 후 'OOV'처리하여 모델링의 성능을 저하했던 'OOV'문제도 해결한다.
- 두 문장이 들어왔다는 걸 알려준다.
Step 3. 두 문장을 구분한단 의미에 구분자 [SEP]를 넣어 분리한다.
- pre-trained 일 경우 input을 2개 문장씩 넣어주고, fine-tuning 시 분류할 목적이라면 input에 문장을 하나만 넣어준다.
모든 sentence의 첫번째 token은 언제나
[CLS](special classification token) 입니다. 이[CLS]token은 transformer 전체층을 다 거치고 나면 token sequence의 결합된 의미를 가지게 되는데, 여기에 간단한 classifier를 붙이면 단일 문장, 또는 연속된 문장의 classification을 쉽게 할 수 있게 됩니다. 만약 classification task가 아니라면 이 token은 무시하면 됩니다.
-
Segment Embedding>"[
Sentence Embedding]. 문장 순서 정보가 있다. 즉, 의미 있는 여러 subword(내부 단어)로 임베딩 한다."Step 1. 위 Step 3에서 구분한 구분자로 두 문장을 하나의 Segment로 지정하여 입력한다. 토큰 시킨 단어들을 다시 하나의 문장으로 만든다.
첫 번째 문장 속 단어는 전부 1로, 두 번째 문장 속 단어는 전부 2로 임베딩한다.
BERT에서는 이 한 세그먼트를 512 sub-word 길이로 제한하는데, 한국어는 보통 20 sub-word가 한 문장을 이룬다고 하며 대부분의 문장은 60 sub-word가 넘지 않는다고 하니 BERT를 사용할 때, 하나의 세그먼트에 128로 제한하여도 충분히 학습이 가능하다고 합니다.
출처: ebb and flow
-
Position Embedding>"[Position Embedding]. 단어 순서 정보"
Step 1. 순서정보를 입력하면 저장 + 공식에 맞춰 벡터화(수치화) 시킨다. Token 순서 대로 인코딩 한다.
Pre-Training 단계
데이터들을 임베딩하여 훈련시킬 데이터를 모두 인코딩 하였으면, 사전훈련을 시킬 단계입니다. 기존의 방법들은 보통 문장을 왼쪽에서 오른쪽으로 학습하여 다음 단어를 예측하는 방식이거나, 예측할 단어의 좌우 문맥을 고려하여 예측하는 방식을 사용합니다.
하지만 BERT는 언어의 특성을 잘 학습하도록,
MLM(Masked Language Model)NSP(Next Sentence Prediction)위 두가지 방식을 사용합니다.
논문에서는 기존(좌우로 학습하는 모델)방식과 비교하여 MLM방식이 더 좋은 성능을 보여주고 있다고 말합니다!
출처: ebb and flow
Task 1. MLM
- MLM: Masked LM
-
양방향+단방향을 concatnate 한다.
- 이를 통하여 LM의 left-to-right을 통하여 문장 전체를 predict하는 방법론과는 달리, [MASK] token 만을 predict하는 pre-training task를 수행.
- 많은 training step이 필요하지만, 보통 LM보다 훨씬 빠르고 좋은 성능을 낸다.
Denoising ~ [mask]
- AE에서는 학습 시, 미리 잡음을 섞어 추후에 입력될지 모르는 잡음을 제거(Denoising)할 수 있도록 모델링을 해둔다. BERT에서도 [mask] 개념을 사용하여 Denoising AE와 같은 역할을 수행하도록 학습한다.
I love you → I [mask] you
- [mask]: noise 처리된 단어를 [mask] 처리함
- 이때 주변단어를 이용하여 [mask]된 단어가 나오도록 알아맞추게 학습한다.
- Pre-traning: [mask] 사용
- Fine-tuning: [mask] 안 사용
- 해당 token을 맞추어 내는 task를 수행하면서, BERT는 문맥을 파악하는 능력이 생긴다.
- 80% 단어(token)을 [MASK]로 바꾼다. eg., my dog is hairy -> my dog is [MASK]
- 10% token을 random word로 바꾼다. eg., my dog is hariy -> my dog is apple
- 10%는 원래 token로 그대로 둔다. 이는 실제 관측된 단어를 bias해주기 위해 실시한다.
- TransFormer의 Encoder에서도 사용한다.
Task 2. NSP
-
문장과 문장 간의 관계
- 두 문장 학습
- NSP: Next Sentence prediction
-
input 단계에서 붙여진 [CLS], [SEP]를 확인한다. 그리고 두 문장을 이어 붙이곤, 이게 원래의 corpus에서도 바로 이어 붙여져 있던 문장인지를 맞추는 binarized next sentence prediction task를 수행한다.
- 연속된 2문장인 A문장과 B문장을 확인하고, A문장 뒤에 B문장이 이어서 나오는 구나,를 파악한다
- Special token: [CLS], [SEP]이 추가되어 있는 점이 Transformer와의 차이점이다.
- [CLS]: 문장 시작
- [SEP]: 단어 구분자
-
원리:
- A 다음 B가 나오면 IsNEXT로 분류한다.
- A 다음 엉뚱하게 C가 나오면 NotNext로 분류한다.
주의
-
Transformer에서는 만든 SentencePiece를 입력값에 넣을 수 있었지만, BERT는 안된다.
- Input layer에서 자동으로 SentencePiece 처리를 해준다.
-
codeZhao HG keras-bert 中 .encode()
ids, segments = tokenizer.encode(text, max_len=SEQ_LEN) - Finetuning의 경우, pre-traing 당시 학습 안 된 단어는 OOV로 자동 처리한다.
CODE
활용
-
BERT 활용 방법: 대량의 코퍼스를 BERT 모델에 넣어 학습하고, BERT 출력 부분에 추가적인 모델(RNN, CNN 등의 ML/DL 모델)을 쌓아 목적을 수행한다.
-
BERT를 사용하지 않은 일반 모델링 >
분류를 원하는 데이터 → LSTM, CNN 등의 머신러닝 모델 → 분류
-
BERT를 사용한 모델링 >
관련 대량 코퍼스 → BERT → 분류를 원하는 데이터 → LSTM, CNN 등의 머신러닝 모델 → 분류
- 이때 DNN을 이용하였을 때와 CNN등 과 같은 복잡한 모델을 이용하였을 때의 성능 차이가 거의 없다고 알려져 있다.
-

- QQP
- Q&A
- Classification
- Tagging
QQP 예시
- QQP : "Input된 Q1과 Q2가 얼마나 유사한가? 유사한 문장인가?" 를 따지는 것.
QA 예시
- (챗봇) Qustion & Answer에 활용한다.
- SQuAD 모델: <START>와 <END>가 나오도록 하는 모델
-
설명 알고리즘 설명 지문이 주어지고, Where ~? 라는 질문을 받으면 Seoul Korea라고 y값을 내놓을 수 있게 지문의 위치를 strat = 13이고 end =14라고 학습한다. [CLS] Question [SEP] 지문 [SEP] 질문에 답을 달아놓을 수 있게, 지문의 몇 번째 있는 단어가 정답인지에 대해 학습을 한다.
Stance Classification(분류)
- 일반 LSTM은 문장 내에서 단어들의 흐름을 보지만, Stance classification은 여러 문장들의 서로의 관련성을 보고 classification를 한다.
code ~ model.summary()
- Zhao HG 의 keras_BERT code 를 활용하였다.
- Pre_trained data는 Google Research를 활용하였다.

-
참고:
- 아마추어 퀀트, blog.naver.com/chunjein
- mino-park7. 2018.10.12. "BERT 논문정리". https://mino-park7.github.io/nlp/2018/12/12/bert-%EB%85%BC%EB%AC%B8%EC%A0%95%EB%A6%AC/?fbclid=IwAR3S-8iLWEVG6FGUVxoYdwQyA-zG0GpOUzVEsFBd0ARFg4eFXqCyGLznu7w. Mino-Park7 NLP Blog
- ebb and flow. 2020. 2. 12. "[BERT] BERT에 대해 쉽게 알아보기1 - BERT는 무엇인가, 동작 구조". https://ebbnflow.tistory.com/151
- Zhao HG. "keras-bert". https://github.com/CyberZHG/keras-bert
- Google Research. "2/128 (BERT-Tiny)". https://github.com/google-research/bert. bert
- SKTBrain. "KoBERT". https://github.com/SKTBrain/KoBERT